Data has become a critical asset class, yet licensing models must evolve to address privacy regulations and ethical concerns. GDPR, CCPA, and sector-specific rules constrain how personal data can be collected, processed, and shared. Organisations that treat data purely as a commodity risk fines, reputational damage, and contractual breach. The shift toward privacy-by-design and purpose limitation demands new licensing structures that explicitly address consent, retention, and downstream use.
Anonymisation and pseudonymisation reduce identifiability but do not eliminate risk. True anonymisation—where re-identification is not reasonably possible—may fall outside data protection rules, but achieving it is harder than many assume. K-anonymity, differential privacy, and synthetic data generation offer technical paths; each has trade-offs between utility and privacy. Synthetic data, generated to mimic statistical properties of real datasets without containing actual records, is gaining traction for training AI and enabling research without exposing individuals.
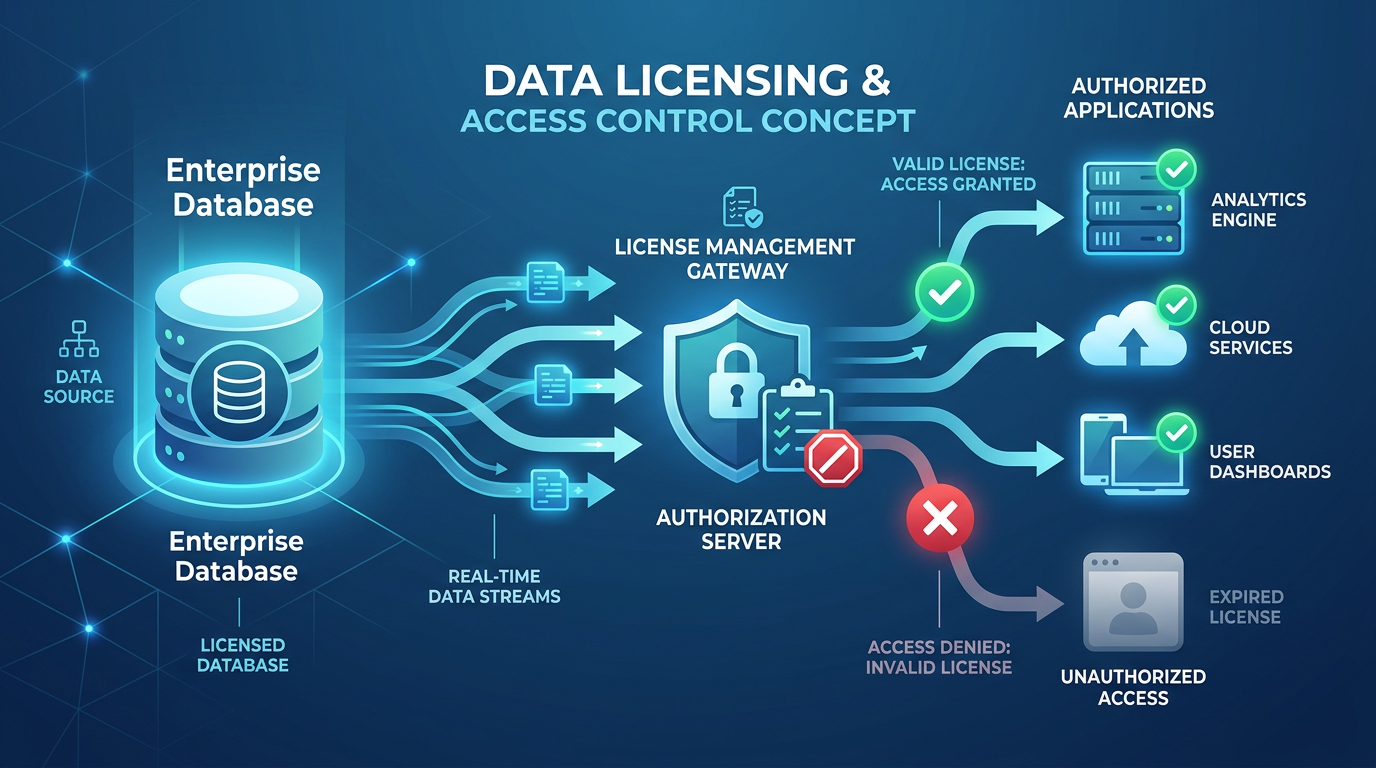
Licensing structures must specify permitted uses, territories, duration, and sublicensing rights. Data-as-a-service (DaaS) models often combine access fees with usage-based pricing. Escrow and audit clauses protect licensors; indemnities and liability caps protect licensees. Consider whether the licence grants ownership of derivatives or only a right to use; downstream commercialisation rights can significantly affect valuation. Standard form agreements rarely suffice for high-value or sensitive datasets.
Valuation Considerations
Data asset value depends on uniqueness, quality, and compliance. A dataset that can be recreated from public sources has limited value. One with exclusive access, clean lineage, and documented consent commands a premium. Factor in refresh costs, retention requirements, and regulatory change. Data decays; static datasets lose value over time. Structure licences to reflect ongoing value delivery where appropriate.
B2B vs Consumer Data
Enterprise data licensing differs from consumer. B2B datasets often have clearer provenance, contractual consent, and defined use cases. Industry data—financial, healthcare, supply chain—commands premiums when unique and compliant. Consumer data faces tighter regulation; consent fatigue and privacy tools have reduced addressable inventory. The shift favours first-party data and compliant third-party sources over legacy list brokers.
AI and Training Data
Machine learning has created demand for large, labelled datasets. Licensing training data requires clarity on permitted model use, retention of copies, and rights to model outputs. Some licensors prohibit use in models that could compete with their products; others require attribution or revenue share. Generative AI has intensified scrutiny: training on copyrighted or personal data without proper rights creates legal and reputational risk. Document provenance and rights at acquisition; downstream users will demand it.
At Fullcover, we approach data asset valuation by assessing uniqueness, compliance posture, and monetisation potential. A database with clear provenance, documented consent, and robust governance commands a premium over datasets with uncertain lineage. We favour licensing models that align incentives—revenue sharing, performance clauses, and clear exit terms—and we factor regulatory risk into every deal. Data assets are valuable, but only when structured and licensed with care.